译者:陈广
日期:2021-1-21
略...(请参考原文)
略...(请参考原文)
略...(请参考原文)
略...(请参考原文)
本节给出两个详细示例,显示Gen 2 RFID标签的系列化全球标识号(SGTIN)和EPC内存区之间的编码和解码,以及显示所有EPC schemes的各种编码的摘要示例。
由于这些仅仅是说明性示例,因此在所有情况下,编码和解码的最终规则均应参考本规范中指明的规范性章节。本节中的图表和随附注释并非编码或解码的完整规范,而是仅用于说明标准编码和解码程序如何工作的要点。编码其他类型标识符的过程在很大程度上是不同的,应参考本规范的相应章节。
此示例演示了使用SGTIN-96 EPC scheme将包含序列化全球贸易商品代码(SGTIN)的GS1元素字符串编码为EPC Gen 2 RFID标签,中间步骤包括EPC URI、EPC Tag URI和EPC二进制编码。
在某些应用中,仅和此次演示的一部分相关。例如,应用程序可能仅需要将GS1元素转换为EPC URI,这种情况下,只需要演示的前几步。
下面的演示参考了以下说明:
0);(c)所对应的十进制数字的数值小于$2^{38}$(小于274,877,906,944)。对于所有其它系列号,必须使用SGTIN-198 EPC scheme。请注意,无论在RFID标签中使用的是SGTIN-96还是SGTIN-198,EPC URI是相同的。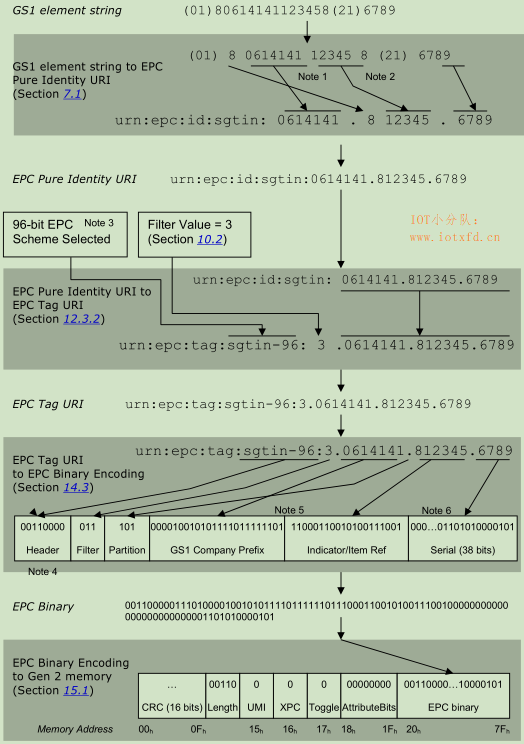
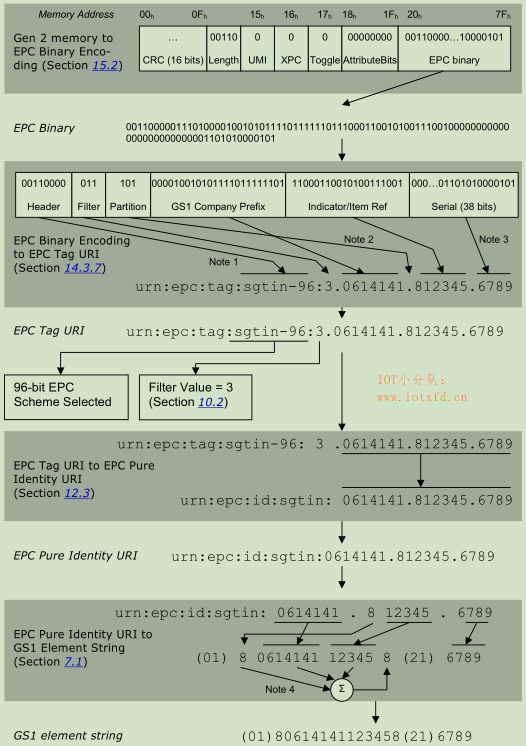
此例演示了将包含SGTIN-96 EPC二进制编码的EPC Gen 2 RFID标签解码为包含序列化全球贸易项目代码(SGTIN)的GS1元素字符串,中间步骤包括EPC二进制编码、EPC Tag URI和EPC URI。
在某些应用中,仅与此次演示的一部分相关。例如,应用程序可能只需要将EPC二进制编码转换为EPC URI,在这种情况下,只需要演示的前几个步骤。
下面的演示参考了以下说明:
在以下所有示例中,GS1公司前缀假定为7位长度。
| SGTIN-96 | |
|---|---|
| GS1元素字符串 | (01) 80614141123458 (21) 6789 |
| EPC URI | urn:epc:id:sgtin:0614141.812345.6789 |
| EPC Tag URI | urn:epc:tag:sgtin-96:3.0614141.812345.6789 |
| EPC二进制编码(十六进制) | 3074257BF7194E4000001A85 |
| SGTIN-198 | |
|---|---|
| GS1元素字符串 | (01) 70614141123451 (21) 32a/b |
| EPC URI | urn:epc:id:sgtin:0614141.712345.32a%2Fb |
| EPC Tag URI | urn:epc:tag:sgtin-198:3.0614141.712345.32a%2Fb |
| EPC二进制编码(十六进制) | 3674257BF6B7A659B2C2BF100000000000000000000000000000 |
| SSCC-96 | |
|---|---|
| GS1元素字符串 | (00) 106141412345678908 |
| EPC URI | urn:epc:id:sscc:0614141.1234567890 |
| EPC Tag URI | urn:epc:tag:sscc-96:3.0614141.1234567890 |
| EPC二进制编码(十六进制) | 3174257BF4499602D2000000 |
| SGLN-96 | |
|---|---|
| GS1元素字符串 | (00) 106141412345678908 |
| EPC URI | urn:epc:id:sgln:0614141.12345.5678 |
| EPC Tag URI | urn:epc:tag:sgln-96:3.0614141.12345.5678 |
| EPC二进制编码(十六进制) | 3274257BF46072000000162E |
| SGLN-195 | |
|---|---|
| GS1元素字符串 | (414) 0614141123452 (254) 32a/b |
| EPC URI | urn:epc:id:sgln:0614141.12345.32a%2Fb |
| EPC Tag URI | urn:epc:tag:sgln-195:3.0614141.12345.32a%2Fb |
| EPC二进制编码(十六进制) | 3974257BF46072CD9615F8800000000000000000000000000 |
| GRAI-96 | |
|---|---|
| GS1元素字符串 | (8003) 006141411234525678 |
| EPC URI | urn:epc:id:grai:0614141.12345.5678 |
| EPC Tag URI | urn:epc:tag:grai-96:3.0614141.12345.5678 |
| EPC二进制编码(十六进制) | 3374257BF40C0E400000162E |
| GRAI-170 | |
|---|---|
| GS1元素字符串 | (8003) 0061414112345232a/b |
| EPC URI | urn:epc:id:grai:0614141.12345.32a%2Fb |
| EPC Tag URI | urn:epc:tag:grai-170:3.0614141.12345.32a%2Fb |
| EPC二进制编码(十六进制) | 3774257BF40C0E59B2C2BF100000000000000000000 |
| GIAI-96 | |
|---|---|
| GS1元素字符串 | (8004) 06141415678 |
| EPC URI | urn:epc:id:giai:0614141.5678 |
| EPC Tag URI | urn:epc:tag:giai-96:3.0614141.5678 |
| EPC二进制编码(十六进制) | 3474257BF40000000000162E |
| GIAI-202 | |
|---|---|
| GS1元素字符串 | (8004) 061414132a/b |
| EPC URI | urn:epc:id:giai:0614141.32a%2Fb |
| EPC Tag URI | urn:epc:tag:giai-202:3.0614141.32a%2Fb |
| EPC二进制编码(十六进制) | 3874257BF59B2C2BF10000000000000000000000000000000000 |
| GSRN-96 | |
|---|---|
| GS1元素字符串 | (8018) 061414112345678902 |
| EPC URI | urn:epc:id:gsrn:0614141.1234567890 |
| EPC Tag URI | urn:epc:tag:gsrn-96:3.0614141.1234567890 |
| EPC二进制编码(十六进制) | 2D74257BF4499602D2000000 |
| GSRNP-96 | |
|---|---|
| GS1元素字符串 | (8017) 061414112345678902 |
| EPC URI | urn:epc:id:gsrnp:0614141.1234567890 |
| EPC Tag URI | urn:epc:tag:gsrnp-96:3.0614141.1234567890 |
| EPC二进制编码(十六进制) | 2E74257BF4499602D2000000 |
| GDTI-96 | |
|---|---|
| GS1元素字符串 | (253) 06141411234525678 |
| EPC URI | urn:epc:id:gdti:0614141.12345.5678 |
| EPC Tag URI | urn:epc:tag:gdti-96:3.0614141.12345.5678 |
| EPC二进制编码(十六进制) | 2C74257BF46072000000162E |
| GDTI-174 | |
|---|---|
| GS1元素字符串 | (253) 4012345987652ABCDefgh012345678 |
| EPC URI | urn:epc:id:gdti:4012345.98765. ABCDefgh012345678 |
| EPC Tag URI | urn:epc:tag:gdti-174:3.4012345.98765.ABCDefgh012345678 |
| EPC二进制编码(十六进制) | 3E74F4E4E7039B061438997367D0C18B266D1AB66EE0 |
| CPI-96 | |
|---|---|
| GS1元素字符串 | (8010) 061414198765 (8011) 12345 |
| EPC URI | urn:epc:id:cpi:0614141.98765.12345 |
| EPC Tag URI | urn:epc:tag:cpi-96:3.0614141.98765.12345 |
| EPC二进制编码(十六进制) | 3C74257BF400C0E680003039 |
| CPI-var | |
|---|---|
| GS1元素字符串 | (8010) 06141415PQ7/Z43 (8011) 12345 |
| EPC URI | urn:epc:id:cpi:0614141.5PQ7%2FZ43.12345 |
| EPC Tag URI | urn:epc:tag:cpi-var:3.0614141.5PQ7%2FZ43.12345 |
| EPC二进制编码(十六进制) | 3D74257BF75411DEF6B4CC00000003039 |
| SGCN-96 | |
|---|---|
| GS1元素字符串 | (255) 401234567890104711 |
| EPC URI | urn:epc:id:sgcn:4012345.67890.04711 |
| EPC Tag URI | urn:epc:tag:sgcn-96:3.4012345.67890.04711 |
| EPC二进制编码(十六进制) | 3F74F4E4E612640000019907 |
| GID-96 | |
|---|---|
| EPC URI | urn:epc:id:gid:31415.271828.1414 |
| EPC Tag URI | urn:epc:tag:gid-96:31415.271828.1414 |
| EPC二进制编码(十六进制) | 350007AB70425D4000000586 |
| USDOD-96 | |
|---|---|
| EPC URI | urn:epc:id:usdod:CAGEY.5678 |
| EPC Tag URI | urn:epc:tag:usdod-96:3.CAGEY.5678 |
| EPC二进制编码(十六进制) | 2F320434147455900000162E |
| ADI-var | |
|---|---|
| EPC URI | urn:epc:id:adi:35962.PQ7VZ4.M37GXB92 |
| EPC Tag URI | urn:epc:tag:adi-var:3.35962.PQ7VZ4.M37GXB92 |
| EPC二进制编码(十六进制) | 3B0E0CF5E76C9047759AD00373DC7602E7200 |
| ITIP-110 | |
|---|---|
| GS1元素字符串 | (8006) 040123451234560102 (21) 981 |
| EPC URI | urn:epc:id:itip:4012345.012345.01.02.981 |
| EPC Tag URI | urn:epc:tag:itip-110:0.4012345.012345.01.02.981 |
| EPC二进制编码(十六进制) | 4014F4E4E40C0E40820000000F54 |
| ITIP-212 | |
|---|---|
| GS1元素字符串 | (8006) 040123451234560102 (21) mw133 |
| EPC URI | urn:epc:id:itip:4012345.012345.01.02.mw133 |
| EPC Tag URI | urn:epc:tag:itip-212:0.4012345.012345.01.02.mw133 |
| EPC二进制编码(十六进制) | 4114F4E4E40C0E4082DBDD8B36600000000000000000000000000000 |
略...(请参考原文)
略...(请参考原文)
请参考原文
Packed Objects格式提供了对有用户数据的有效编码和访问。与No-Directory和Directory Access方法相比,Packed Objects格式提供了更高的编码效率,部分原因是利用了复杂的压缩方法,一部分是通过在每个Packed Object的前端(在对其任何数据进行编码之前)定义一个固有的目录结构,该结构支持随机访问,同时减少一些先前方法的固定开销,另一部分是通过利用数据系统特定的信息(例如固定长度应用程序标识符的GS1定义)。
Packed Objects的正式描述见本附录和附录 J、K、L和M:
此外,请注意,根据ISO/IEC 15961-2的过程,用于Packed Object的特定ID表的所有描述都是单独注册的,这是注册ID表的机器可读格式的完整形式描述。
Packed Object 内存格式由一个或多个“Packed Objects”数据结构的内存序列组成。每个Packed Object可以包含编码数据或目录信息,但不会同时存在。内存中的第一个Packed Object的前面是DSFID。DSFID指示使用Packed Object作为内存的访问方法,并指示注册的数据格式是该内存中每个Packed Object的默认格式。每个Packed Object的前面或后面都可以选择填充模式(如果需要在字或块边界上对齐)。此外,内存中最多有一个Packed Object可以选择在前面加一个指向Directory Packed Object的指针(这个指针本身可以选择加在填充后面)。这一系列Packed Object可以选择在结尾处填充一个或多个零值八位字节以边界对齐。参见图I 3-1,其中显示了出现在RFID标签中时的顺序。
注意: 因为一个编码的Packed Object中的数据结构是位对齐而不是字节对齐,本附录使用术语“八位字节”而不是“字节”,除非在字节边界上必须对齐8-bit数量。
| DSFID | 可选指针*和/或填充 | 第一个Packed Object | 可选指针*和/或填充 | 可选的第二个Packed Object | ... | 可选的Packed Object | 可选指针*和/或填充 | 零值八位字节 |
* 说明: Directory Packed Object的可选指针在内存中最多只能出现一次。
每个Packed Object表示一个或多个数据系统标识符的序列,每个标识符通过引用注册数据格式的Base ID表中的条目来指定。条目由其在Base表中的相对位置参考;此相对位置或Base表索引在本规范中称为“ID值”。有两种不同的Packed Object方法可用于通过引用其ID值来表示标识符序列:
ID List是默认的Packed Object格式,因为相比ID Map而言,它使用更少的位,如果列表只包含数据系统定义的ID值的一小部分。然而,如果Packed Object包含超过大约四分之一的已定义条目,则ID Map需要更少的位。例如,如果数据系统有16个条目,那么每个ID值(表索引)是一个4-bit的值,一个包含4个ID值的列表所占用的位与完整ID Map所占用的位相同。ID Map的固定长度特性使得它特别适合在Directory Packed Object中使用,Directory Packed Object列出了内存中所有Packed Object中的所有标识符(参见第I.9节)。Packed Object的整体结构相同,无论是IDLPO还是IDMPO,如图I 3-2所示以及在下一小节描述。
| 可选的格式标志 | 对象信息或部(IDLPO或IDMPO) | 辅助ID部(如果需要) | Aux格式部(如果需要) | 数据部(如果需要) |
通过在对象信息部的末尾添加一个可选的Addendum子部,可以使Packed Object成为“可编辑的”,该子部包括一个指向“Addendum Packed Object”的指针,其中添加和/或删除了内容。可编辑的“父”和“子”Packed Object的一个或多个这样的“链”可以出现在内存中Packed Object的整个序列中,但是Directory Packed Objects的链不能超过一个。
每个Packed Object由几个位对齐部组成(也就是在部之间没有填充位),部是几个八位字节。所有必需的和可选的Packed Object格式都包含在以下排序的Packed Object部列表中。在此列表之后,介绍了每个Packed Object部,本附件的后面部分详细描述了每个Packed Object部。
格式标志: Packed Object可以选择以模式0000开头,该模式保留用于引入一个或多个格式标志,如I.4.2节所述。这些标志可能表示使用非默认ID Map格式。如果不存在格式标志,则Packed Object默认为ID List格式。
对象信息: 所有的Packed Object都包含一个对象信息部,它包含了对象长度信息和ID值信息:
ID List(IDLPO)对象信息格式:
ID Map(IDMPO)对象信息格式:
辅助ID位: 如果需要编码为某些类别的ID定义的附加位(这些位完成ID的定义),Packed Object可能包含一个辅助ID部。
Aux格式位: 如果存在编码一或多个位以定义对数据压缩的支持,Data Packed Object可能包含一个Aux格式部,但对于ID的定义没有帮助。
数据部: Data Packed Object包含一个数据部,表示与Packed Object中列出的每个标识符关联的压缩数据。此部在Directory Packed Object和使用非目录压缩的Packed Object中被省略。根据相关ID表中数据格式的声明,数据部将包含两个子部中的一个或两个:
| 对象信息,在一个默认ID List PO | |||
| 对象长度 | ID数量 | ID List | 可选的Addendum |
| 对象信息,在一个非默认ID List PO | ||
| 对象长度 | ID List部(一或多个列表) | 可选的Addendum |
| 对象信息,在一个ID Map PO | ||
| ID Map部(一个或多个Map) | 对象长度 | 可选的Addendum |
在Packed Objects访问方法下,内存的默认布局由一个前导DSFID组成,紧跟着一个ID List Packed Object(在下一个字节边界处),然后可选地附加ID List Packed Object(每个都从下一个字节边界处开始),并在下一个字节边界处由一个零值八位字节终止(表示没有额外的Packed Object被编码)。本节定义可能出现在Packed Object预期开始处的有效格式标志模式,以便在需要时覆盖默认布局(例如,通过更改Packed Object的格式,或通过插入填充模式在字或块边界上对齐下一个Packed Object)。定义的模式集如下所示。
| 位模式 | 描述 | 附加信息 | 所在小节 |
|---|---|---|---|
| 0000 0000 | 终止模式 | 随后没有更多的Packed Object | I.4.1 |
| LLLLLL xx | IDLPO的第一个八位字节 | 任意LLLLLL > 3 | I.5 |
| 0000 | 格式标志开始模式 | (如果全EBV-6为非零) | I.4.2 |
| 0000 10NA | IDLPO: N=1:非默认信息 A=1:Addendum存在 |
如果N=1:允许多ID表 如果A=1:对象信息部的结尾存在Addendum ptr(s) |
I.4.3 |
| 0000 01xx | Inter-PO模式 | 目录指针或填充 | I.4.4 |
| 0000 0100 | 表示填充八位字节 | 后面没有填充长度指示 | I.4.4 |
| 0000 0101 | 表示运行长度填充 | 跟随EBV-8长度 | I.4.4 |
| 0000 0110 | RFU | I.4.4 | |
| 0000 0111 | 目录指针 | 跟随EBV-8模式 | I.4.4 |
| 0000 11xx | ID Map Packed Object | I.4.2 | |
| 0000 0001 0000 0010 0000 0011 |
[无效] | 无效模式 |
在Packed Object的预期开始处有八个或更多0位的模式表示剩余内存中不再存在Packed Object。
请注意:Packed Object预期开始处的六个连续0位(如果解释为Packed Object)表示长度为零的ID List Packed Object。
前导模式为0000的非零EBV-6用作格式标志部指示模式。初始0000格式标志指示模式之后的附加位定义如下:
10(生成初始模式000010)表示携带至少一个非默认可选特性的IDLPO(见I.4.3)。11表示IDMPO,它是使用ID Map格式而不是ID List格式的Packed Object(见I.9),ID Map部紧跟在这个两位模式之后。01表示在下一个Packed Object开始之前的外部模式(填充模式或指针)(见I.4.4)。一个小于4的前导EBV-6对象长度作为Packed Object长度是无效的。
注意: 最短可能的Packed Object是IDLPO,对于每个ID值使用4位的数据系统,它对单个ID值进行编码。此Packed Object具有总数14个的固定位。因此,一个双八位字节Packed Object将只包含两个数据位,是无效的。一个三八位字节Packed Object可以对单个数据项进行编码,其长度可达三位数。为了在这种情况下将“3”保留为无效长度,Packed Object编码器应编码一个前导格式标志部(如果需要,所有选项都设置为零),以便将对象长度增加到4。
“000010”出现在Packed Object的预期开始处,后跟两个附加位,以形成完整的IDLPO格式标志部000010NA,其中:
如果第一个附加位N为1,那么IDLPO对象信息部采用非默认格式。默认IDLPO格式只允许一个ID List(使用注册的默认Base ID表),而可选的非默认IDLPO对象信息格式支持一个或多个ID List的序列,并且每个这样的列表都以标识它所代表的注册表的信息开始(见I.5.1)。
如果第二个附加位A为1,则在对象信息部结尾存在Addendum子部。
000001出现在Packed Object的预期开始处,用于指示填充或目录指针,如下所示:
11表示Directory Packed Object指针遵循该模式。指针长度为一或多个八位字节,EBV-8格式。指针可以为空(为0的值),但如果为非零,则指示从指针开始到Directory Packed Object(如果是可编辑的,则应是其“链”中的第一个)开始的八位字节个数。例如,如果目录指针的格式标志字节在字节偏移量1处编码,指针本身占用从偏移量2开始的字节,目录从偏移量9开始,那么目录指针编码为EBV-8格式的值7。Directory Packed Object指针可以出现在内存中第一个Packed Object之前,也可以出现在Packed Object可能开始的任何其他位置,但在给定的数据载体内存中只能出现一次,并且(如果非空)必须位于比它指向的目录更低的地址。此指针后面的第一个八位字节可能是填充(定义如下)、一组新的格式标志模式或ID List Packed Object的开头。00表示完整的八位模式00000100用作填充字节,以便下一个Packed Object可以从所需的字或块边界开始。必要时可重复该模式以实现所需的对齐。01作为运行长度填充指示符,后面紧跟一个EBV-8表示从EBV-8开始到下一个Packed Object开始的八位字节数(例如,如果下一个Packed Object紧跟其后,EBV-8的值为1)。这种机制消除了为了填充一个大的内存块而需要写很多字的内存。10保留。每个Packed Object的对象信息部即包含长度信息(Packed Object的尺寸,单位为bit和八位字节),也包含ID值信息。Packed Object对一个或多个数据系统标识符的表示进行编码,并且(如果是Data Packed Object)还对其关联的数据元素(AI字符串、DI字符串等)进行编码。ID值信息对Packed Object中编码的所有标识符(AIs、DIs等)或(Directory Packed Object中)内存中任何位置编码的所有标识符的完整列表进行编码。
为了节省编码和传输的位,数据系统标识符(每个标识符通常在数据系统中由两个、三个或四个ASCII字符表示)在Packed Object中由ID值表示,它表示注册Base表中指示ID值的项的索引。单个ID值可以表示单个对象标识符,或者可以表示常用的对象标识符序列。在某些情况下,ID值表示相关对象标识符的“类”,或其中一个或多个对象标识符被可选地编码的对象标识符序列;在这些情况下,辅助ID位(参见I.6)被编码以指定在Packed Object被编码时选择了哪个选择或选项。“完全限定的ID值”(FQIDV)是一个ID值,加上一个特定的辅助ID位选择(如果ID值的表条目调用了任何辅助ID位)。特定完全限定ID值的一个实例可能只出现在数据载体的Data Packed Object中,但是特定ID值可能出现不止一次,如果每次都由不同的辅助ID位“限定”。如果一个ID值出现了不止一次,则所有出现都应出现在单个Packed Object中(或Packed Object及其附录的单个“链”中)。
为编码ID值定义了两种方法:ID List Packed Object使用ID值位域的可变长列表,而ID Map Packed Object使用固定长度的位数组。除非Packed Object的格式由初始格式标志模式修改,否则Packed Object的格式默认为包含单个ID List的ID List Packed Object(IDLPO)的格式,该ID List的ID值对应于注册数据格式的默认Base ID表。可选的格式标志可以将ID部的格式更改为IDMPO格式,或者更改为IDLPO格式编码ID List部(它支持多个ID表,包括非默认数据系统)。
尽管对象信息分中的信息顺序因所选格式而异(见I.5.1),但每个Packed Object的对象信息部应提供I.5.2中定义的长度信息和I.5.4或I.5.5中定义的ID值信息(见I.5.3)。对象信息部(IDLPO或IDMPO的)允许以可选Addendum子部结束(见I.5.6)。
默认的IDLPO对象信息格式用于Packed Object,既可以不带前导格式标志部,也可以带格式标志部,该部指示具有可能的Addendum和默认对象信息部的IDLPO。默认的IDLPO对象信息部包含一个ID List(如果格式标志指示,可以选择后跟一个Addendum子部)。默认IDLPO对象信息部的格式如下表所示。
| 域名称 | Length Information | NumberOfIDs | ID Listing | Addendum subsection |
|---|---|---|---|---|
| Usage: | 此对象中八位字节的个数,加上最后一个八位字节填充指示 | 此对象中ID值的个数(减1) | 单个ID值列表;值的尺寸取决于注册数据格式 | 指向包含编辑信息的其他对象的可选指针 |
| Structure: | 可变:见I.5.2 | 可变:EBV-3 | 见I.5.4 | 见I.5.6 |
在IDDLP的对象信息部中,NumberOfIDs域是一个EBV-3扩展位向量,由扩展位的一个或多个重复后面跟着2个值位组成。这个EBV-3编码的数量比相关ID List上的ID值少一个。例如,101 000的EBV-3表示(4+0+1)=5个ID值。所有Packed Object的长度信息如I.5.2所述。接下来的字段是ID List(见I.5.4)和可选Addendum子部(见I.5.6)
前导格式标志可以改变IDLPO的对象信息结构,使其在ID List部中包含多个ID Listing(也允许使用非默认ID表)。非默认的IDLPO对象信息结构如下表所示。
| Field Name: | Length Info | ID List部,第一个List | 可选附加ID List | 空App指示符(单个0位) | Addendum子部 | ||
|---|---|---|---|---|---|---|---|
| Application Indicator | Number of IDs | ID Listing | |||||
| Usage: | 此对象中八位字节的个数加上最后一个八位字节填充指示符 | 指示选中的ID表和每个条目的尺寸 | 列表中ID值的个数(减去1) | 列出ID值,然后一个F/R使用位 | 0或多个重复列表,每个对应一个不同的ID表 | 其它包含编辑信息对象的可选指针 | |
| Structure: | 见I.5.2 | 见I.5.3.1 | 见I.5.1.1 | 见I.5.4及I.5.3.2 | 引用上一列 | 见I.5.3.1 | 见I.5.6 |
前导格式标志可将对象信息结构定义为IDMPO,其中长度信息(和可选Addendum子部)跟随ID Map部分(见I.5.5)。这种安排确保了ID Map位于给定应用程序的固定位置,这在用作目录时非常有用。IDMPO对象信息结构如下表所示。
| 域名称: | ID Map部 | 长度信息 | Addendum |
|---|---|---|---|
| Usage: | 一或多个ID Map结构,每个使用不同的ID表 | 此对象的八位字节的个数加上最后一个八位字节填充指示符 | 其它包含编辑信息对象的可选指针 |
| Structure: | 见I.9.1 | 见I.5.2 | 见I.5.6 |
长度信息的格式,总在存在于任意Packed Object的对象信息部中,如下表所示。
| 域名称: | ObjectLength | Pad Indicator |
|---|---|---|
| Usage: | 此对象的8-bit字节个数,包括此Packed Object的第一个字节,包括它的IDLPO/IDMPO格式标志(如果存在的话)。不包括Packed Object之间的模式,如I.4.4所述 | 如果为1:对象的最后一个字节包含至少一个填充 |
| Structure: | 可变:EBV-6 | 固定:1 bit |
第一个域 ObjectLength 是一个EBV-6扩展位向量,由一个或多个扩展位和5个值位的重复组成。一个EBV-6的000100(值为4)表示一个4字节Packed Object,一个EBV-6的100001 000000(值为32)表示一个32字节对象等等。
注册数据格式定义(至少)Base ID表(注册ID表的详细规范见附录J)。此Base表定义了由表的每一行表示的数据系统标识符、每个表项调用的任何辅助ID位或Aux格式位,以及解码系统在解释根据每个表项编码的数据时应使用的各种隐式规则(取自预定义的规则集)。当数据项在Packed Object中编码时,其相关联的表条目由条目在Base表中的相对位置标识。此表位置或索引是Packed Object中表示的ID值。
包含给定条目数的Base表固有地指定了对ID List Packed Object中的表索引(即ID值)进行编码所需的位数(作为条目数的日志( Base 2))。由于当前和将来的数据系统ID表在表条目的数量方面将以不可预测的方式变化,因此需要预先定义ID值大小机制,该机制允许将来扩展以容纳新表,同时尽量减少解码器的复杂度,尽量减少需要升级解码软件(除了添加新的表)。因此,无论定义的Base表条目的确切数量如何,每个Base表定义都应使用表I 5-5中定义的ID值编码的预定义大小之一(任何未使用的条目应标记为保留,如附录J所示)。只有当Packed Object使用非默认Base ID表时,ID Size位模式才在Packed Object中编码。表中的某些条目表示的大小不是2的整数幂。 当从使用这种大小的表中对ID值进行编码(到IDLPO中)时,每对ID值都是通过将该对的较早ID乘以表I-5-5的第四列中指定的Base并将该对的较晚ID相加来编码的,并且将结果编码为第四列中指定的位数。如果此ID表有一个尾随的单个ID值,则按下表第三列中指定的位数进行编码。
| ID Size位模式 | 表条目最大值 | 每单个或尾部ID值的位数目,以及如何编码 | 每对ID值的位数目以及如何编码 |
|---|---|---|---|
| 000 | 最多16 | 4,as 1 Base 16 value | 8, as 2 Base 16 values |
| 001 | 最多22 | 5,as 1 Base 22 value | 9, as 2 Base 22 values |
| 010 | 最多32 | 5,as 1 Base 32 value | 10, as 2 Base 32 values |
| 011 | 最多45 | 6,as 1 Base 45 value | 11, as 2 Base 45 values |
| 100 | 最多64 | 6,as 1 Base 64 value | 12, as 2 Base 64 values |
| 101 | 最多90 | 7,as 1 Base 90 value | 13, as 2 Base 90 values |
| 110 | 最多128 | 7,as 1 Base 128 value | 14, as 2 Base 128 values |
| 1110 | 最多256 | 8,as 1 Base 256 value | 16, as 2 Base 256 values |
| 111100 | 最多512 | 9,as 1 Base 512 value | 18, as 2 Base 512 values |
| 111101 | 最多1024 | 10,as 1 Base 1024 value | 20, as 2 Base 1024 values |
| 111110 | 最多2048 | 11,as 1 Base 2048 value | 22, as 2 Base 2048 values |
| 111111 | 最多4096 | 12,as 1 Base 4096 value | 24, as 2 Base 4096 values |
Application Indicator子部可用于指示默认或非默认ID表中ID值的使用。此小节在每个IDMPO中都是必需的,但仅在使用支持多个ID List的非默认格式的IDLPO中是必需的。
Application Indicator由以下组件组成:
0,表示没有附加的ID List或Map跟随。注意,在对象信息部的第一个List或Map中,此位总是省略。当此位存在并为0时,下面的所有位域都不被编码。1,则表示使用了注册的ID表,而不是内存的默认值。如果为1,则该位后面紧跟着根据ISO/IEC 15961注册的数据格式的9位表示。000表示。然而,也可以在注册中定义多达七个备用Base表(具有不同的ID大小),并且可以通过编码的子集模式指示从这些Base表中的选择。该特征可用于定义完整数据系统的较小的特定于扇区或特定于应用程序的子集,从而实质性地减小编码ID Map的尺寸。当考虑使用新的ID表注册或外部数据系统的注册时,应用程序设计人员可以使用“restricted use”编码选项,该选项会给Packed Object增加一些开销,但在交换过程中会产生一种格式,该格式可以由不拥有新的或外部ID表的接收系统完全解码。除了使用默认对象信息格式的IDLPO之外,在Data或Directory Packed Object的ID Map部部或ID List部中表示每个ID表之后,立即对一个Full/Restricted Use位进行编码。在Directory Packed Objec中,此位应始终设置为0,并忽略其值。如果编码器希望在IDLPO中使用“restricted use”选项,则应在IDLPO的前面添加一个调用非默认对象信息格式的格式标志部分。
如果“Full/Restricted Use”位为0,则来自相应注册ID表的数据字符串的编码将充分利用ID表的IDstring和FormatString信息。如果位是1,那么这意味着一些编码开销被添加到辅助ID部和(在Packed-Object压缩的情况下)Aux格式部,因此没有访问表的解码器仍然可以根据J.4.1中指定的方案从Packed Object输出OID和数据。具体而言,设置为1的 Full/Restricted Use位表示:
每个ID值在一个IDLPO中的位域列表中表示;列表中位字段的数量由NumberOfIDs字段确定(见第I.5.6.2节)。每个ID值位域的长度在4到11位的范围内,这取决于它所表示的Base表索引的大小。在IDLPO的对象信息部的可选非默认格式中,单个Packed Object可能包含多个ID List子分,每个子部引用不同的ID表。在此非默认格式中,每个ID列表子部由一个应用程序指示符子部(如果以“0”位开头,则终止ID列表)组成,后跟一个EBV-3 numberOfID、一个ID List和一个Full/Restricted Use标志。
当表示相对大量的ID值(占大Base表项的10%以上,或占小Base表项的25%左右)时,编码ID Map可能比编码ID值列表更有效。当在ID Map中编码时,每个ID值由其在映射中的相对位置表示(例如,第一ID Map位表示ID值0,第三位表示ID值2,最后一位表示ID值n(对应于具有(n+1)个条目的Base表的最后一个条目)。ID Map中每个位的值指示对应的ID值是存在(如果位为1)还是不存在(如果位为0)。ID Map始终作为ID Map部结构的一部分进行编码(参见I.9.1)。
Packed Object Addendum功能支持基本编辑操作,特别是添加、删除或替换以前编写的Packed Object中的单个数据项的功能,而无需重写整个Packed Object。不包含Addendum子部的Packed Object不能以这种方式编辑,如果需要更改,则必须完全重写。
Addendum子部由Reverse Links位、Child位和一个或两个EBV-6链接组成。来自Data Packed Object的链接只能作为附加物指向其他Data Packed Object;来自Directory Packed Object的链接只能作为附加物指向其他Directory Packed Object。标准的Packed Object结构规则适用,有一些限制在I.5.6.2中描述。
Reverse Links位应在同一“链”的每个Packed Object中设置相同。Reverse Links位定义如下:
0,则此Packed Object链中的每个子都位于高于其父的内存位置。到子的链接被编码为当前Packed Object的最后一个八位字节和子的第一个八位字节之间的八位字节数(加一)。到父级的链接被编码为位于父级Packed Object的第一个八位字节和当前压缩对象的第一个八位字节之间的八位字节数(加一)。1,则此Packed Object链中的每个子的内存位置都低于其父。到子的链接被编码为当前压缩对象的第一个八位字节和子的第一个八位字节之间的八位字节数(加一)。到父级的链接被编码为当前压缩对象的最后一个八位字节和父级的第一个八位字节之间的八位字节数(加一)。Child位定义如下:
0,则此Packed Object是可编辑的“Parentless” Packed Object(即链的第一个),在这种情况下,Child位后面紧跟着一个EBV-6链接,指向第一个“子”Packed Object,该Packed Object包含父的编辑补遗。1,则此Packed Object是已编辑“parent”的可编辑“child”,该位后面紧跟着一个指向“parent”的EBV-6链接和第二个指向下一个“子”Packed Object的EBV-6行,该Packed Object包含父的编辑addenda。链接值为零是空指针(不存在子),并且在Child位为0的Packed Object中,这表示Packed Object可编辑,但尚未编辑。提供到父的链接,使得目录可以指示Addendum Packed Object中的ID值的存在和位置,同时仍然提供询问器有效地定位与原始“父”Packed Object在逻辑上相关联的其他ID值的能力。链接值为零作为指向父级的指针无效。
为了给足够大的链接留出空间,当在编码父节点时下一个“child”的未来位置未知时,允许使用EBV-6的“redundant”形式(例如使用“100000 000000”来表示零的链路值)。
只有在IDLPO中,“子”ID List Packed Object的每个Addendum部包含一组“EditingOp”位紧跟着它最后的EBV-6链接编码,这样的位的数目是根据Addendum Packed Object的ID List上的条目的数目来确定的。对于此列表上的每个ID值,相应的EditingOp位定义如下:
1表示对应的完全限定ID值(FQIDV)被替换。替换操作的效果是,应忽略与此Addendum Packed Object的FQIDV匹配的FQIDV原始关联的数据,并在逻辑上替换为此Addendum Packed Object中编码的Aux格式位和数据)注意: 如果一个应用程序一次请求几个“编辑”操作(包括一些删除或替换操作以及添加操作),那么如果添加操作共享Addendum开销,而不是在新的Packed Object中实现,那么实现可以实现更高效的编码。
包含Addendum子部的Packed Objects在结构上与其他Packed Objects相同。然而,以下观察结果适用:
Packed Objects设计要求包括一项要求,即编码在Packed Objects中的所有数据系统标识符(AI、DI等)都可以完全识别,而无需扩展压缩数据,即使某些ID值仅提供部分限定的标识符。结果,如果任何ID值调用辅助ID位,则对象信息部后面应跟随辅助ID位部。示例包括用于标识一组相关物流AI的第三位的四位域。
为了完全指定标识符,可以根据需要出于多种原因调用辅助ID位。例如,单个ID表条目的ID值可以指定两个相似标识符之间的选择(在编码时需要一个编码位来选择两个ID中的一个),或者可以指定所需标识符和可选标识符的组合(需要一个编码位来启用或禁用每个选项)。可用的机制在附录J中进行了描述。所有产生的辅助ID位域在该次要ID位部中串联,顺序与在Packed Object中列出的调用它们的ID值相同。请注意,辅助ID位部的定义是相同的,不管Packed Object是IDLPO还是IDMPO,但并不存在于目录IDMPO中。
Data Packed Object的Aux格式部对解码过程的辅助信息进行编码。Directory Packed Object不包含Aux格式部。在Data Packed Object中,Aux格式部以下表中定义的“Compact-Parameter”位开始。
| 位模式 | 在此Packed Object中使用的压缩方法 | 所在小节 |
| 1 | “Packed-Object”压缩 | 见I.7.2 |
| 000 | “Application-Defined”,如非目录访问方法的定义 | 见I.7.1 |
| 001 | “Compact”,如非目录访问方法的定义 | 见I.7.1 |
| 010 | “UTF-8”,如非目录访问方法的定义 | 见I.7.1 |
| 011bbbb | (bbbb应在1...14之间):保留未来定义 | I.7.1 |
如果Compact-Parameter位模式为1,那么Aux格式部的剩余部分将如I.7.2描述进行编码;否则,Aux格式部的剩余部分将如I.7.1描述进行编码。
如果Compact-Parameter位选择了任何非目录压缩方法,则Compact-Parameter位之后是字节对齐填充模式,该模式由零个或多个0位和单个1位组成,以便将1之后的下一位作为下一个字节的最高有效位对齐。
下一个字节被定义为“无目录数据部”的第一个八位字节,用于代替I.8中描述的数据位。此Packed Object的数据字符串按照Packed Object的对象信息部指示的顺序进行编码,并按照[ISO15962](无目录访问方法的编码规则)的附录D进行压缩,但以下两个例外:
0。因此,ID表条目调用的每个数据字符串在修改后的数据集结构中分别编码为:
<modified precursor> <length of compacted object> <compacted object octets>
<compacted object octets>按照[ISO15962]的D.1.1和D.1.2进行确定和编码,<length of compacted object>按照[ISO15962]的D.2进行确定和编码。
在最后一个数据集之后,不应对0的终止前驱值进行编码(解码系统使用Packed Object中被编码的ObjectLength识别数据的结尾)。
如果Packed-Object压缩方法是由Compact-Parameter位选择的,则压缩参数位后面紧跟着零个或多个辅助格式位,这可能由该压缩对象中使用的ID表条目调用。然后,Aux格式位后面紧跟着一个数据段,该数据段使用I.8中描述的压缩对象压缩方法。
设计用于Packed-Object压缩方法的ID表条目可以调用各种类型的辅助信息,而不仅仅是ID本身的完整指示(例如用于指示可变数据长度的位字段,以帮助数据压缩过程)。所有这样的位字段都按照ID List或Map所要求的顺序连接在这一portion中。注意,无论Packed Object是IDLPO还是IDMPO,Aux Format部分的定义都是相同的。
ID表条目为表中未指定为固定长度的所有条目调用Aux Format length位(但是,如果这些长度位与Packed Object的A/N子部分中编码的最后一个数据项相对应,则这些长度位实际上不会被编码)。此信息允许解码系统将解码的数据解析成适当长度的字符串。编码的Aux Format length条目使用可变位数,根据数据项允许的最短和最长数据字符串之间的指定范围确定,如下所示:
00表示3的长度。1111后跟4位,表示从15(0000)到29(1110)的值)。1111 1111后跟4位表示从30(0000)到44(1110)的值)。注意:
数据部总是存在于Packed Object中,除Directory Packed Objectr或Directory Addendum Packed Object(无数据元素编码),Data Addendum Packed Object只包含删除操作,以及使用无目录压缩的Packed Object(见I.7.1)的情况。当存在数据部时,它将跟随对象信息部(以及辅助ID和Aux格式部,如果存在的话)。根据编码的ID和数据字符串的特征,数据部可以按以下顺序包括两个子部中的一个或两个:已知长度的数字子部和字母数字子部。以下段落提供了这些数据部分各子部的详细说明。如果数据部的所有子部都在Packed Object中使用,则数据部的布局如下表所示。
| 已经长度数字子部 | 字母数字子部 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| A/N首部位 | 二进制数据段 | ||||||||||
| 1stKLN Binary | 2ndKLN Binary | ... | Last KLN Binary | Non-Num Base Bit(s) | Prefix Bit,Prefix Run(s) | Suffix Bit,Suffix Run(s) | Char Map | Ext’d.Num Binary | Ext’d Non-Num Binary | Base 10 Binary | Non-Num Binary |
对于总是数字的数据字符串,ID表可以指示固定数量的数字(该固定长度信息不在Packed Object中编码)和/或可变数量的数字(在这种情况下,字符串的长度在Aux格式部分中编码,如上所述)。当在FormatString列(见J.2.3)中指定一个数据项包含一个固定长度的数字字符串,后跟一个可变长度的字符串时,数字字符串在已知长度数字子部中编码,字母数字字符串在字母数字子部中编码。
固定长度信息(直接从ID表派生)加上可变长度信息(如前所述,从编码位派生)的总和将导致当前Packed Object中编码的每个始终是数字的字符串的“已知长度条目”。Packed Object中的每个全数字数据字符串(如果在ID表中描述为全数字)通过将数字字符串转换为单个二进制数(最多160位,表示0和($10^{48}-1$)之间的二进制值)进行编码。附录K中的图K-1显示了表示给定位数量所需的位数。如果一个全数字字符串包含的数字超过48位,那么前48位将被编码为一个160-bit的组,然后是下一个最多48位的组,依此类推。最后,将对象中每个全数字数据字符串的二进制值本身串联起来,形成已知长度的数字子部。
字母数字(A/N)子部(如果存在)将Packed Object的所有数据从任何尚未在已知长度数字子部中编码的数据字符串进行编码。如果没有要编码的字母数字字符,则省略整个A/N子部。字母数字子部可以对数字和非数字ASCII字符的任意组合或八位数据进行编码。此数据中的数字字符单独编码,平均效率为每位数4.322 bit或更好,具体取决于字符序列。非数字字符以平均效率独立编码,每字符5.91 bit或更好(所有大写字母),最坏情况限制为每字符9 bit(如果字符混合需要非数字字符的Base 256编码)。
字母数字子部由一系列A/N首部位(见I.8.2.1)组成,后跟一到四个二进制段(每个段表示以单个数字基编码的数据,如Base 10或Base 30,见I.8.2.4),必要时进行填充以完成最后一个字节(见I 8.2.5)。
A/N首部位定义如下:
0表示为非数字基选择Base 30;10表示为非数字基选择Base 74;11表示为非数字基选择Base 2560(表示未对字符映射前缀进行编码)或1后跟I.8.2.3中定义的六个前缀位的一个或多个“运行”。0(表示未对字符映射后缀进行编码)或1后跟I.8.2.3中定义的六个后缀位的一个或多个“运行”。通过首先将数据字符串联成单个数据字符串(单个字符串长度已经记录在Aux格式部分中),可以实现字母数字数据字符串的有序列表(不包括已经在已知长度数字子部中编码的数据字符串)的压缩。每个数据字符被分类为Base 10(对于数字)、Base 30的非数字字符(主要是大写A-Z)、Base 74的非数字字符(包括大写和小写字母以及其他ASCII字符)或以256为基数的字符。这些字符集在附录K中有完整的定义。通过使用一个额外的“shift”值(与Base 256集中大多数较低的128个字符一样),Base 74集的所有字符也可以从Base 30访问。根据“native”Base 30值与数据字符串中其他值的相对百分比,选择其中一个基作为非数字基的更有效选择。
接下来,使用称为“字符映射”的可变长度位模式记录和编码数字和非数字字符的精确序列,其中每个0表示Base 10的值(编码一个数字),每个1表示非数字字符的值(在所选基中)。注意,(例如)如果选择了Base 30编码,则每个数据字符(大写字母和空格字符除外)需要由一对Base 30值表示,因此每个这样的数据字符由字符映射中的一对1位表示。
为了在串联序列包括来自相同基的六个或更多值的运行的情况下提高效率,提供了一个或多个前缀或后缀“Runs”(单基字符序列)的可选Run-Length表示,其可以替换字符映射的第一和/或最后portion。编码器不应创建将Shift值与其下一个(shifted)值分离的运行,因此运行始终表示源字符的整数。
可选的前缀表示(如果存在)由前缀运行的一个或多个实例组成。每个前缀运行由一个Run Position位、两个Basis位和三个Run Length位组成,定义如下:
0)表示至少有一个Prefix Run在该Prefix Run之后进行编码(表示当前集合右侧的另一组源字符)。Run Postion位(如果为1)表示当前Prefix Run是A/N子部的最后一个(最右侧)Prefix Run。1)表示所选基扩展为包括来自“opposite”基的字符。因此,00表示Base 10的运行长度编码序列;01表示Base 13编码的主要(但不完全)数字序列;10表示在A/N首部中选择的非数字基数的值序列,11表示一系列值,这些值主要来自非数字基,但也扩展到包括数字字符。注意一个例外:如果在A/N头中选择的非数字基是Base 256,则“extended”版本定义为Base 40。可选的后缀表示(如果存在)是一系列一个或多个Suffix Runs,每个Suffix Runs的格式与刚才描述的Prefix Run的格式相同。与该描述一致,请注意,如果为1,则运行位置位表示当前后缀运行是A/N子部的最后一个(最右侧)后缀运行,因此任何前面的Suffix Runs都表示该最后Suffix Runs左侧的源字符。
紧跟在字符映射的最后一位之后,最多可对四个二进制数进行编码,每个二进制数表示在单个基本系统中编码的所有字符。首先,对一个base-13位序列进行编码(如果一个或多个Prefix或Suffix Runs以进行base-13编码)。如果存在,则该位序列直接表示将分类为Base 13的所有前缀和后缀字符(按该顺序)的组合序列(忽略没有这样分类的任何中间字符)编码为单个值,或者换句话说,应用Base 13到二进制转换而产生的二进制数。此序列中要编码的比特数直接由所表示的base-13值的数目确定,如由base-13序列的前缀和后缀运行长度之和所调用的那样。给定Base 13值的位数由附录K中的图确定。接下来,对Extended-NonNumeric Base段(Base 40或Base 84)进行类似的编码(如果任何Prefix或Suffix Runs时需要Extended-NonNumeric编码)。
接下来,对Base 10的二进制段进行编码,该二进制段直接表示通过将前缀和/或字符映射和/或后缀中的数字序列(忽略任何中间的非数字字符)编码为单个值而产生的二进制数,或者换句话说,应用Base 10的二进制转换。此序列中编码的位数直接由所表示的位数决定,如附录K所示。
紧跟在Base 10位序列的最后一位(如果有)之后,对非数字(Base 30、Base 74或Base 256)位序列进行编码(如果字符映射指示至少一个非数字字符)。此位序列表示数据中的非数字字符序列(忽略任何中间数字)的Base 30到二进制转换(或Base 74到二进制转换,或Base 256值的直接传输)产生的二进制数。同样,编码位的数量直接由所表示的非数字值的数量决定,如附录K所示。注意,如果选择Base 256作为非数字基,则编码器可以自由地将每个数字分类和编码为Base 10或Base 256(Base 10将更为有效,除非被利用长前缀或后缀的能力)。
请注意,字母数字小节以几个可变长度的位域(字符映射和一个或多个二进制部(表示数字和非数字二进制值))结束。进一步注意,这三个可变长度位域的长度都没有被显式编码(尽管也可以存在一个或两个扩展的基二进制段,但是它们具有根据前缀和/或后缀运行确定的已知长度)。为了确定这三个可变长度字段之间的边界,解码器需要实现一个过程,使用剩余数据位数的知识,以便正确解析字母数字部分。附录M中描述了此类程序的示例。
最终二进制段的最后一位(最低有效位)也是Packed Object的最后一位有效位。如果在最后一个字节中有任何剩余的位位置要用填充位填充,则最高有效的填充位应设置为1,任何剩余的较低有效的填充位应设置为0。解码器可以通过检查Packed Object的长度部(如果该部分的Pad Indicator位为1,还可以通过检查Packed Object的最后一个字节)来确定Packed Object中非填充位的总数。
当编码相对大量的ID值时,ID Map可以比ID值列表更有效。另外,ID Map表示对于在Directory Packed Object中使用是有利的。ID Map本身(每个ID Map部的第一个主要子部)的结构是相同的,无论是在Data还是Directory IDMPO中,但是Directory IDMPO的ID Map部包含附加的可选子部。包含一个或多个ID Map的ID Map部的结构在下面的部分中进行了描述,并根据其在数据IDMPO中的用法进行了说明;后面的部分将解释在Directory IDMPO中添加的结构元素。
IDMPO使用称为ID Map部的结构表示ID值,该结构包含一个或多个ID Map。在Data IDMPO中编码的每个ID值在ID Map位域中表示为1,其固定长度等于相应Base表中的条目数。相反,ID Map域中的每个0表示没有相应的ID值。由于ID Map字段中1位的总数等于所表示的ID值的数量,因此不会对NumberOfIDs域进行显式编码。为了实现此表示形式所能实现的功能范围,ID Map部包含ID Map本身以外的元素。如果存在,可选的ID Map部紧跟指示IDMPO的前导模式(如I.4.2所述),并按以下顺序包含以下元素:
1,则一个Addendum子部将存在于对象信息部的尾部(在对象长度信息之后)。这些元素在下表中显示为最大结构(每个元素都存在),将在下一小节中进行描述。
| 第一个ID Map | 可选附加ID Map(s) | 空App指示符(单个0位) | 数据/目录指示符位 | (如果为目录)可选AuxMap部 | Closing Flag位 | ||
|---|---|---|---|---|---|---|---|
| App指示符 | ID Map位域(以F/R位结尾) | App指示符 | ID Map域(以F/R位结尾) | ||||
| 见I.5.3.1 | 见I.9.1.1和I.5.3.2 | 与之前一样 | 与之前一样 | 见I.5.3.1 | 见表 I-12 | Addendum标志位 | |
当一个ID Map部被编码时,它总是跟在一个Object Length和Pad指示符后面,并且可选地跟在一个Addendum子部后面(所有这些都是先前定义的),然后可以跟在为Packed Object定义的任何其他部后面,除了Directory IDMPO不应包括一个数据部。
ID Map通常由应用程序指示符和ID Map位域组成,以Full/Restricted Use位结尾。ID Map位域由单个“MapPresent”标志位组成,然后(如果MapPresent为1)若干位,这些位等于根据应用程序指示符内的ID大小模式确定的长度,再加上一位(Full/Restricted Use位)。ID Map位域指示与特定注册的主或备用基表中的条目相对应的编码数据项的存在/不存在。基表的选择由DSFID和ID Map位域前面的应用程序指示符模式的编码组合表示。ID Map位域的MSB对应于基表中的ID值0,下一位对应于ID值1,依此类推。
在Data Packed Object的ID Map位域中,每个1位表示此Packed Object包含与此ID Map相关联的已注册基表中的条目对应的数据项的编码引用。请注意,有效的编码条目可以在链的第一个(“无父”)Packed Object(包含ID Map的对象)或该链的Addendum IDLPO中找到。进一步注意,一个或多个数据条目可在IDMPO中编码,但标记为“无效”(通过附录IDLPO中的删除条目)。
ID Map不应对应于辅助ID表而不是Base ID表。注意,在“无父”数据IDMPO中编码的数据项应以它们在相关Base表中列出的相同相对顺序出现。但是,可以通过向对象追加Addendum IDLPO,将其他“无序”数据项添加到现有数据IDMPO中。
ID Map不能指示具有相同ID值的特定数量的实例(大于一个),这似乎意味着在Data IDMPO中只能对使用给定ID值的一个数据实例进行编码。然而,ID-Map方法需要支持两个或更多编码数据项来自同一标识符“class”(并因此共享相同的ID值)的情况。以下机制解决了这一需要:
ID Map部可以包含多个ID Map;空应用程序指示符部(其AppIndicatorPresent位设置为0)终止ID Map列表。
Data/Directory指示符位总是紧跟在最后一个ID Map之后进行编码。根据定义,数据IDMPO的Data/Directory位设置为0,而目录IDMPO的Data/Directory位设置为1。如果Data/Directory位设置为1,则紧跟其后的是AuxMap指示符位,如果为1,则表示紧跟其后的是可选AuxMap部。
ID Map部以单个Closing Flag结尾:
1,则表示在Packed Object的对象信息部的结尾处编码了可选的Addendum子部。如有Addendum子部,如第I.5.6节所述。“Directory Packed Object”是其目录位设置为1的IDMPO。它与数据IDMPO唯一固有的区别是它不包含任何编码的数据项。但是,其他机制和使用注意事项仅适用于Directory Packed Object,下面的小节将对此进行描述。
尽管ID Masp的结构在Data或Directory IDMPO中都是相同的,但结构的语义有些不同。在Directory Packed Object的ID Map位域中,每个1位表示同一数据载体内存库中的Data Packed Object包含与此ID Map的指定Base表中的相应项相关联的有效数据项。可选地,Directory Packed Object可以进一步指示哪个Packed Object包含每个数据项(参见下面可选AuxMap部的描述)。
注意,与Data IDMPO相反,在目录的ID Map中的位的顺序和这些数据项随后在Data Packed Object序列内的存储器中编码的顺序之间不需要相关。
AuxMap部可选地允许Directory IDMPO的ID Map不仅指示标签的内存区中是否存在所有数据项,而且还指示哪个Packed Object对每个数据项进行编码。如果AuxMap指示符位是1,则AuxMap部应在该位之后立即编码。如果编码,AuxMap部应包含一个PO索引字段,用于该部分前面的每个ID Map。在最后一个PO索引域之后,AuxMap部可以选择性地编码ObjectOffset列表,其中每个ObjectOffset通常指示从上一个Packed Object的开始到下一个Packed Object的开始的字节数。下表中显示了这个AuxMap结构(例如带有两个ID Map的IDMPO示例)。
| 第一个ID Map的PO索引域 | 第二个ID Map的PO索引域 | Object Offsets Present位 | 可选ObjectOffsets子部 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| POindex Length | POindex Table | POindex Length | POindex Table | Object Offsets Multiplier | Object1 offset(EBV6) | Object2 offset(EBV6) | ... | ObjectN offset(EBV6) | |
每个PO索引域具有以下结构和语义:
一个三位的POindexLength域,表示为紧跟在该字段后面的PO索引表中的每个条目编码的索引位的数目(除非POindex长度是000,这意味着没有PO索引表紧跟其后)。
PO索引表,由一个位数组组成,在这个directory Packed Object的相应ID Map中,每个位对应一个位(或一组位,取决于POIndexLength)。PO索引表条目(即“PO Index”)表示(按相对顺序)哪个Packed Object包含ID Map中相应的1位所指示的数据项。如果ID映射位为0,则存在相应的PO索引表项,但忽略其内容。
每个Packed Object都按顺序分配一个索引值,而不考虑它是“无父” Packed Object还是另一个Packed Object的“子”,也不考虑它是Data还是Directory Packed Object。
如果PO索引在目录“chain”的第一个PO索引表(用于关联的ID Map)内,则:
如果PO索引不在关联ID Map的目录链的第一个PO索引表中(即,它在Addendum IDMPO中),则:
如果ID值的有效实例位于Addendum Packed Object中,则实现可以选择将PO索引设置为直接指向该Addendum,或者可以改为继续指向链中最初包含ID值的Packed Object。注意:第一种方法有时导致更快的搜索;第二种方法有时导致更快的目录更新。
在最后一个PO索引字段之后,AuxMap部以(至少)一个“ObjectOffsets Present”位结束。此位的0值表示未对ObjectOffsets子部进行编码。如果该位是1,则紧跟其后的是ObjectOffsets子部,该子部包含EBV-6“offsets”列表(Packed Object开始和下一个Packed Object开始之间的八位字节数)。如果存在,ObjectOffsets子部由ObjectOffsetsMultiplier和Object Offsets列表组成,定义如下:
在许多应用中,询问器可以选择读取包含一个或多个感兴趣的“目标”数据项的任何数据载体的全部内容。在这种应用中,在初始读取操作期间不需要存储器中那些数据项的位置信息;在该处理阶段仅需要Presence/Absence指示。ID Map可以形成用于指示此类应用中的数据载体的内容的特别有效的Presence/Absence在目录。完整目录结构对数据载体中每个数据元素的偏移量或地址(内存位置)进行编码,这需要写入大量位(通常每个数据项32位或更多)。不可避免地,这种方法还需要通过空中读取大量位,以确定特定标签上是否存在感兴趣的标识符。相反,当仅需要Presence/Absence信息时,使用ID Map仅使用数据系统中定义的每个数据项的一个比特来传送相同的信息。整个ID Map通常可以表示为128位或更少,并且随着更多的数据项被写入标签而保持相同的大小。
“Presence/Absence目录” Packed Object被定义为不包含PO索引的Directory IDMPO,因此不提供关于单个数据项驻留在数据载体中的位置的编码信息。通过在Addendum Packed Object中添加PO索引,作为Presence/Absence Packed Object的“子”,可以将Presence/Absence目录转换为“索引目录”Packed Object(见I.9.2.4)。
在许多涉及大内存的应用程序中,询问程序可以选择读取覆盖整个内存内容的目录部,然后发出后续读取以获取感兴趣的“目标”数据项。在这样的应用程序中,这些数据项在内存中的位置信息很重要,但是如果随着时间的推移许多数据项被添加到一个大内存中,目录本身可能会增长到不需要的大小。
ID Map与包含PO索引的AuxMap结合使用,可以形成特别有效的“索引目录”,用于指示RFID标签的内容及其大致位置。与对数据载体中每个数据元素的偏移量或地址(内存位置)进行编码的完整标记目录结构不同,索引目录对小的相对位置或索引进行编码,指示哪个Packed Object包含每个数据元素。应用设计者还可以选择如上所述在可选的objectoffset子部中对每个Packed Object的位置进行编码,以便解码系统在单独读取索引目录时能够计算存储器中所有Packed Object的起始地址。
通过大多数数据系统的规则,以这种方式使用的ID Map的效用得到了增强,即给定的标识符在单个数据载体中只能出现一次。当索引目录与后续对象中数据的Packed Object编码一起使用时,此规则可以使用相对较少的目录位提供对读取数据的几乎完全随机访问。例如,ID Map目录(每个定义的ID一位)可以与附加的AuxMap“PO Index”数组相关联(例如,使用每个定义的ID三位)。使用这种安排,询问程序将读取Directory Packed Object,并检查其ID Map以确定所需的数据项是否存在于标签上。如果是这样,它将检查与该数据项对应的3个“PO Index”位,以确定标签上的前8个Packed Object中包含所需数据项的是哪个。如果对可选的ObjectOffsets子段进行了编码,则询问器可以直接计算所需Packed Object的起始地址;否则,询问器可以执行连续的读取操作以获取所需的Packed Object。
Packed Object注册数据格式文件由一系列“关键字行”和一个或多个ID表组成。空行可能出现在数据格式文件中的任何位置,并且会被忽略。另外,任何一行都可能以额外的空白列结束,这些列也会被忽略。
为了说明文件格式,图J-1中显示了一个假设的数据系统注册。在这个假设的数据系统中,每个ID值都与一个或多个OID和相应的ID字符串相关联。下面的小节解释了图中所示的语法。
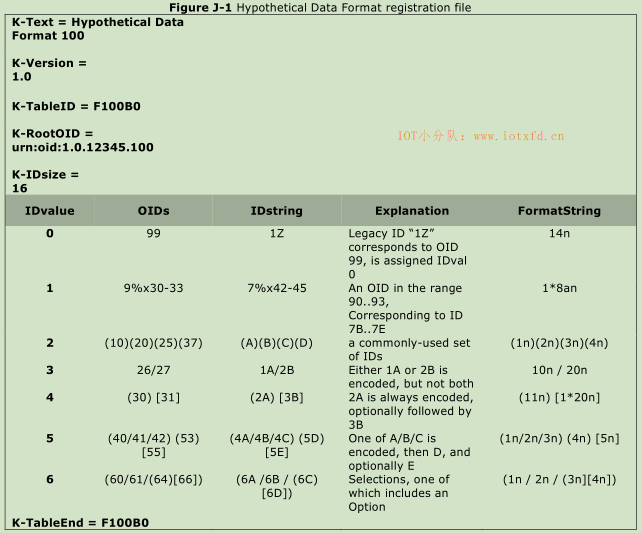
文件头中的关键字行(每个注册文件的第一部分)可以按任何顺序出现,如下所示:
此外,可以使用可选关键词赋值行“K-text = string”包含h”,,并且可以在文件头或表头中出现零次或多次,但不在ID表体中出现。
文件头部分后面有一个或多个表头部(每个部都引入了一个ID表)。每个首部以一个K-TableID关键字行开始,后跟一系列附加的必需关键字行和可选关键字行(可以按任何顺序出现),如下所示:
表头部的末尾是第一个非空行,该行不以关键字开头。第一个非空行应列出紧跟该行的ID表中每一列的标题;列标题区分大小写。
备用Base ID表(如果存在)在格式上与主Base ID表相同(但通常表示针对特定应用程序的较小标识符选择)。
辅助ID表可以由Base表的OIDs列中的关键字调用。辅助ID表相当于Base ID表的单个ID值的单个选择列表(参见J.3)(除了次要表使用K-Idsize显式定义每个ID的辅助ID位的数量);次表的IDvalue列列出了次表中每行对应的辅助ID位模式的值。辅助ID表中的OIDs条目本身不得包含选择列表,也不得调用另一个辅助ID表。
每个ID表由一系列的一行或多行组成,每行包括一个强制的“IDvalue”列、几个定义的可选列(如“OIDs”、“IDstring”和“FormatString”)和任意数量的信息列(如上面所示的假设示例中的“Explanation”列)。
每个ID表以所需的关键字行结尾:
所有强制性和可选列的语法和要求应如J.2所述。
Packed Object注册中的每个ID表应包括一个IDvalue列,并可包括本规范中定义为可选的其他列和/或信息列(其列标题未在本规范中定义)。
Packed Object注册中的每个ID表应包括一个IDvalue列。连续行上的ID值应单调增加。但是,在达到包含K-IDsize的关键字行所指示的完整行数之前,表可能会终止。在这种情况下,接收系统将假定所有剩余的ID值都保留用于将来的分配(就好像OIDs列包含关键字“K-RFA”)。如果注册的Base ID表不包括下面描述的可选OIDs列,则IDvalue应用作OID的最后一个arc。
Packed Object注册总是为每个标识符指定一个最终的OID arc(在“OIDs”列中指定的一个数字,如下所述,或者如果该列不存在,则IDvalue被指定为默认的最终arc)。如果单个IDvalue表示OIDs的组合或OIDs之间的选择(表示OIDs选择的任何条目都会调用一个或多个辅助ID位),则OIDs列是必需的,而不是可选的。
Packed Object注册可能包括IDString列,如果存在,它会为每个OID分配一个ASCII字符串名称。如果没有提供名称,系统必须通过其OID引用标识符(见J.4)。然而,许多注册将基于对每个定义的标识符具有ASCII表示的数据系统,并且接收系统可以选择输出基于这些字符串的表示。如果是这样,ID表可能包含一列,指示对应于每个OID的IDstring。空IDstring单元格表示没有与OID关联的相应ASCII字符串。非空IDstring应为该行的OIDs列调用的每个OIDs提供一个名称(如果没有OIDs列,则提供一个名称)。因此,IDstring中的组合和选择操作的顺序应与行的OIDs列中的顺序完全匹配。
非空的OIDs单元格可以包含关键字、表示单个OID值(十进制)的ASCII字符串或定义OID选项和/或组合的复合字符串(ABNF表示法)。此列中复合OID字符串的详细语法(也适用于IDstring列)如第J.3节所定义。OIDs条目可以包含以下关键字之一,而不是包含简单或复合的OID表示:
最后,任何OIDs条目都可以以单个“R”字符结尾(前面有一个或多个空格字符),以指示“Repeat”位应被编码为条目调用的最后一个辅助ID位。如果为“1”,则该位表示此类标识符的另一个实例也被编码(即,该位的作用就像ID值的重复被编码在ID列表上一样)。如果为“1”,则该位后跟另一系列辅助ID位,以表示ID值的这个附加实例的细节。
IDstring列不应包含上述任何关键字条目,当相应的OIDs条目包含关键字时,IDstring条目应为空。
ID表可以可选地定义与特定标识符相关联的数据的数据特征,以便于数据压缩。如果存在,FormatString条目指定数据项是全数字还是字母数字(即,可能包含小数以外的字符),并指定固定长度还是可变长度。如果不存在FormatString条目,则默认数据特征为字母数字。如果不存在FormatString条目,或者该条目未指定长度,则允许任何长度>=1。除非指定了一个固定长度,否则每个编码数据项的长度都在压缩对象的Aux格式部进行编码,如I.7中所述。
如果给定的IDstring条目定义了多个标识符,则相应的FormatString列应显示每个标识符的格式字符串,使用与相应IDstring中使用的相同的标点字符序列(忽略连接)。
单个标识符的格式字符串应为以下之一:
长度限定符应为null(即不存在限定符,表示任何长度>=1是合法的)、单个十进制数(表示固定长度)或形式为“i*j”的长度范围,其中“i”表示数据项的最小允许长度,“j”表示最大允许长度,在后一种情况下,如果省略“j”,则表示最大长度是无限的。
FormatString中“n”对应的数据在KLN子部中编码;FormatString中“an”对应的数据在A/N子部中编码。
当数据项的给定实例在压缩对象中编码时,其长度在I.7.2中指定的Aux格式部中编码。范围的最小值本身不是编码的,而是在ID表的FormatString列中指定的。
示例:
FormatString条目“3*6n”表示一个全数字数据项,其长度始终在3到6位之间(含3到6位)。给定长度用两位编码,其中“00”表示长度为“3”的数字串,“11”表示长度为六位的字符串。
一些注册可能希望指定Packed Object内容的输出表示所需的信息,而不是每个编码标识符的弧的默认OID表示。如果该信息对于特定表是不变的,则注册文件可以包括先前定义的关键字行。如果一个表中的行与行之间的解释不同,那么可以将Interp列添加到ID表中。此列条目(如果存在)可能包含以下一个或多个关键字赋值(用分号分隔),如先前定义的(参见J.1.1和J.1.2):
如果使用,这些值将覆盖(对于特定标识符)默认的文件级值和/或表头部中指定的值。
在给定的ID表条目中,OIDs、IDString和FormatString列可能表示本节中描述的一个或多个机制。J.3.1指定了机制的语义,J.3.2指定了ID表列的形式语法。
在下面的描述中,单词“Identifier”表示OID最终arc(在OIDs列的上下文中)或IDString名称(在IDString列的上下文中)。如果两个列都存在,则只有OIDs列实际调用辅助ID位。
请注意,组合本身不会调用任何辅助ID位(除非其一个或多个组件调用)。
(a)[B][C][D]指示ID值表现标识符A,可选地后跟B、C和/或D。选项列表为括号中的每个组件调用一个辅助ID位,其中“1”表示可选组件已编码。通常,“复合” OIDs或IDstring条目可能包含上述任何或所有操作。但是,为了确保对OIDs条目的单个从左到右的解析会产生一组确定的辅助ID位(按照OIDs条目调用它们的相同从左到右的顺序进行编码),应用了以下限制:
(、)、[、]、%、-、或/,除非如上所述用作运算符。如果其中一个字符是已定义的数据系统标识符“name”的一部分,则应将其表示为单个文字连接字符。在每个ID表条目中,OIDs、IDString和FormatString列的内容应符合以下Expr语法,除非该列为空或(对于OIDs列)包含J.2.2中指定的关键字。这三列共享相同的语法,只是下面指定的每一列的COMPONENT语法不同。在给定的ID表条目中,OIDs、IDString和FormatString列的内容(如果为空则除外)应根据此语法具有相同的解析树,但COMPONENTs可能不同。Expr中的任何地方都允许(并忽略)空格字符,但在组件内部,只有在下面明确指定的地方才允许使用空格。
Expr ::= SelectionExpr | “(” SelectionExpr “)” | SelectionSubexpr
SelectionExpr ::= SelectionSubexpr ( “/” SelectionSubexpr )+
SelectionSubexpr ::= COMPONENT | ComboExpr
ComboExpr ::= ComboSubexpr+
ComboSubexpr ::= “(” COMPONENT “)” | “[" COMPONENT “]”
For the OIDs column, COMPONENT shall conform to the following grammar:
COMPONENT_OIDs ::= (COMPONENT_OIDs_Char | Concat)+
COMPONENT_OIDs_Char ::= (“0”..“9”)+
For the IDString column, COMPONENT shall conform to the following grammar:
COMPONENT_IDString ::= UnquotedIDString | QuotedIDString
UnquotedIDString ::= (UnQuotedIDStringChar | Concat)+
UnquotedIDStringChar ::=
“0”..“9” | “A”..“Z” | “a”..“z” | “_”
QuotedIDString ::= QUOTE QuotedIDStringConstituent+ QUOTE
QuotedIDStringConstituent ::=
“ ” | “!” | “#”..“~” | (QUOTE QUOTE)
QUOTE表示ASCII字符34(十进制),双引号字符。
当使用COMPONENT _ IDString的QuotedIDString形式时,开头和结尾的QUOTE字符不应被视为IDString的一部分。在起始引号和结束引号之间,允许32(十进制)到126(十进制)范围内的所有ASCII字符,但一行中的两个引号字符应表示要包含在IDString中的单个双引号字符。
在QuotedIDString形式中,%字符并不表示串联运算符,而是IDString中包含的百分比字符。要使用串联运算符,必须使用UnquotedIDString形式。在这种情况下,可以使用退化串联运算符(其中起始字符等于结束字符)将不属于UnquotedIDStringChar所列字符之一的字符包含到IDString中。
对于FormatString列,COMPONENT应符合以下语法:
COMPONENT_FormatString ::= Range? (“an” | “n”) | FixedRange “n” “ ”+ VarRange “an”
Range ::= FixedRange | VarRange
FixedRange ::= Number
VarRange ::= Number “*” Number?
Number ::= (“0”..“9”)+
OIDs和IDString列的COMPONENT句法引用Concat,其语法指定如下:
Concat ::= “%” “x” HexChar “-” HexChar
HexChar ::= (“0”..“9” | “A”..“F”)
连字符后面的十六进制值应大于或等于连字符前面的十六进制值。在OIDs列中,每个十六进制值应在$30_{hex}$到$39_{hex}$十六进制(含)的范围内。在IDString列中,每个十六进制值应在$20_{hex}$到$7E_{hex}$(含)的范围内。
向接收系统表示Packed Object内容的默认方法是一系列名称/值对,其中名称是一个OID,值是与该OID关联的解码数据字符串。除非K-RootOID关键字行另有指定,否则默认的根OID为urn:oid:1.0.15961.ff,其中ff是在DSFID中编码的数据格式。OID的最后一个arc(默认情况下)是IDvalue,但通常由OIDs列中的条目覆盖。请注意,编码应用指示符(见I.5.3.1)可能会从DSFID指示的值更改ff。
如果ID表的IDstring列中的信息支持,则接收系统可以基于OID的IDstring表示将OID输出转换为各种可选格式。如ISO/IEC 15434中所描述的一种这样的格式需要两位格式标识符作为附加信息;表注册可以使用如上所述的K-ISO15434关键字提供此信息。
K-RootOID关键字和OIDs列的组合使注册实体能够将OID分配给数据系统标识符,而不考虑它们实际上是如何编码的,因此无论访问方法如何,都可以应用相同的OID分配。
如果接收系统没有访问相关ID表的权限(可能是因为它是新注册的),则Packed Object解码器将没有足够的信息将IDvalue(加上辅助ID位)转换为预期的OID。为了简化新表或外部表的引入,编码器可以选择遵循“限制使用”规则(见I.5.3.2)。
当接收系统已对按照“限制使用”规则编码的Packed Object进行解码,但无法访问指定的ID表时,它应按照以下格式构造“ID Value OID”:
urn:oid:1.0.15961.300.ff.bb.idval.secbits
其中1.0.15961.300是具有保留数据格式“300”的根OID,该格式从未在DSFID中编码,但用于区分“ID值OID”和真实OID(如果ID表可用,则会使用该格式)。保留值300之后是编码表的数据格式(ff)(可能不同于DSFID的默认值)、表ID(bb)(始终为“0”,除非通过编码应用程序指示符另有指示)、编码ID值和调用的辅助ID位的十进制表示。此过程为每个唯一的完全限定ID值创建唯一的OID。例如,使用附录L中所示的假设ID表(但为了说明目的,假设该表的指定根OID为urn:oid:1.0.12345.9,则第四位为“2”的“AMOUNT” ID的真实OID为:
urn:oid:1.0.12345.9.3912
and an “ID Value OID” of
urn:oid:1.0.15961.300.9.0.51.2
当单个ID值通过组合或可选组件表示多个组件标识符时,其多个OID和数据字符串应分别表示,每个ID值OID使用相同的“ID值OID”(上至并包括辅助ID位arc),但将组件编号(从“1”开始表示组件编号)添加为最终arc在该IDvalue下解码的第一个组件)。
如果解码系统遇到引用解码器不可用的ID表的Packed Object,但是编码器选择不在应用指示符中设置“限制使用”位,则解码器应丢弃Packed Object,或者将整个Packed Object作为单个未编码的二进制实体(Packed Object的ObjectLength字段中指定的长度的八位字节序列)中继到接收系统。未编码Packed Object的OID应为urn:oid:1.0.15961.301.ff.n,其中“301”是保留的数据格式,用于指示未编码的Packed Object,“ff”应是在内存开始时在DSFID中编码的数据格式,可选的最终弧“n”可依次递增,以区分多个未编码的Packed Object同一数据载体内存中的Packed Object。
Packed Object主要使用两个编码基:
对于输入数据的非数字字符的高百分比需要成对的Base 30的值的情况,还定义了两个可选的基数,即Base 74和Base 256:
<space>(GS不支持用作数据分隔符)。<GS>(八位字节值$29_{dec}$)表示。最后,在有些情况下,当字符的长运行可以被分类到单个基中时,可以通过基指示符的运行长度编码而不是通过字符映射位来提高压缩效率。为了便于分类,添加了额外的“扩展”基,仅用于前缀和后缀运行。
图B-1中显示了编码Base 10、Base 16、Base 30、Base 40、Base 74和Base 84的各种字符所需的位数。在所有情况下,对单个输入组的大小都进行了限制,选择该组以输出不超过20个八位字节的组。
本章剩余多为表格,略...请参考原文
为了说明编码Packed Object时可以调用的一些技术,下面的示例输入数据由来自假设数据系统的数据元素组成。此数据表示:
应用程序将把上述输入作为OID/值对列表呈现给编码器。产生的输入数据如下所示,表示为单个数据字符串(其中每个OID最终arc显示在括号中):
(7)061031(32)978123456(1)1A23B456CD
该示例使用了一个假想的ID表。在这个假设表中,每个ID值都是Base ID表的7位索引;与这个示例相关的条目如表L-1所示。
编码按下列步骤执行:
111010010011001111101011000000
注意,到目前为止,编码比特的总数是(3+6+1+7+7+4+5+20+30)或83比特,表示IDLPO长度部(假设单个EBV-6向量仍然足以编码Packed Object的长度)、两个7比特ID值、次ID和Aux格式部,和两个已知长度的数字压缩二进制域。
在这个阶段,只有一个非数字数据字符串(对于OID1)需要在字母数字子段中编码。10个字符的源数据字符串是“1A23B456CD”。此字符串不包含需要从基本Base-30字符集中移出Base-30的字符,因此选择Base-30作为非数字基(因此字母数字部的第一位相应地设置为“0”)。数据字符串没有包含来自同一个基的六个或更多连续字符的子字符串,因此接下来的两位被设置为“00”(表示前缀和后缀都不是运行长度编码的)。因此,接下来需要对完整的10位字符映射进行编码。其特定位模式为“0100100011”,表示源数据字符串“1A23B456CD”中特定的数字和非数字序列。
到目前为止,字母数字小节包含13位序列“0 00 0100100011”。根据附录K,可以确定两个最终位序列(对源数据串的Base-10和Base-30分量进行编码)的长度为20位(对于六位数字)和20位(对于使用Base 30的四个大写字母)。源数据字符串“1A23B456CD”的六位数字为“123456”,编码为20位序列:
00011110001001000000
它附加在本段开头引用的13位序列的末尾。
源数据字符串的四个非数字是“ABCD”,它们被转换(使用表K-1)为四个Base-30的值1、2、3和4的序列(在下面的公式中表示为值$v_3$到$v_0$)。然后使用以下公式将其转换为单个二进制值:
$30^3 * v_3 + 30^2 * v_2 + 30^1 * v_1 + 30^0 * v_0$
在本例中,公式计算为 (27000*1+900*2+30*3+1*4),等于070DE(十六进制),编码为20位序列“00000111000011011110”,附加在前20位序列的末尾。因此,字母数字部分包含总计 (13+20+20) 或53位,紧跟在前83位之后,用于压缩对象中总计136个有效位。
最后的编码步骤是计算Packed Object的完整长度(在长度部分内对EBV-6进行编码)并填充最后一个字节(如果需要)。136除以8表示总共需要17个字节来保存Packed Object,并且在最后一个字节中不需要pad位。因此,长度部分的EBV-6部分是“010001”,其中该EBV-6值指示对象中的17个字节。之后,Pad指示符位被设置为“0”,表示最后一个数据字节中不存在填充位。
完整的编码过程可概括如下: 原始输入:(7)061031(32)978123456(1)1A23B456CD 重新排序为:(7)061031(1)1A23B456CD(32)978123456
格式标志部:(空)
对象信息部:
ebvObjectLen:010001
paddingPresent:0
ebvNumIDs:001
IDvals:1111101 0110011
辅助ID部:
IDbits:0010
AUX格式部:
auxFormatbits:1 0101
数据部:
KLnumeric: 0000 11101110 01100111 111010 01001100 11111010 11000000
ANheader: 0
ANprefix: 0
ANsuffix: 0
ANmap: 01 00100011
ANdigitVal: 0001 11100010 01000000
ANnonDigitsVal: 0000 01110000 11011110
Padding: none
Packed Object总位数:136;字节对齐后:136
输出为:44 7E B3 2A 87 73 3F 49 9F 58 01 23 1E 24 00 70 DE
表L-1显示了假想ISO注册数据格式99的假想ID表的相关子集。
| K-Version = 1.0 | |||
|---|---|---|---|
| K-TableID = F99B0 | |||
| K-RootOID = urn:oid:1.0.15961.99 | |||
| K-IDsize = 128 | |||
| IDvalue | OIDs | Data Title | FormatString |
| 3 | 1 | BATCH/LOT | 1*20an |
| 8 | 7 | USE BY OR EXPIRY | 6n |
| 51 | 3%x30-39 | AMOAUNT | 4*18n |
| 125 | (7)(1) | EXPIRY + BATCH/LOT | (6n) (1*20an) |
| K-TableEnd = F99B0 |
解码过程首先将内存的第一个字节解码为DSFID。如果前两位表示Packed Object访问方法,则本附件的其余部分适用。从剩余的DSFID八位字节或八位字节中,确定数据格式,该格式应作为该内存中所有Packed Object的默认数据格式。根据数据格式,确定用于处理每个Packed Object中的ID值的默认ID表。
通常,解码器第一次通过初始ID值列表,如前所述,以便完成标识符列表。如果解码器在Packed Object中找到任何感兴趣的标识符(或者如果它被要求从标记的内存中报告所有数据字符串),那么它将需要记录隐含的固定长度(从ID表)和编码的可变长度(从Aux格式子节),以解析Packed Object的压缩数据。解码器在记录任何可变长度的位模式时,必须首先将它们转换为每个表的可变字符串长度(例如,三位模式可以指示2到9范围内的可变字符串长度)。
从DSFID结束后的第一个字节对齐位置开始,解析剩余的内存内容,直到编码数据结束,重复本节的其余部分,直到到达终止模式。
根据前导位模式(见I.4)确定以下哪种情况适用:
如果Packed Object有一个格式标志部分,那么这个部分可以指示Packed Object是ID Map格式,否则它是ID List格式。根据指定的格式,解析Object Information部以确定Packed Object中包含的对象长度和ID信息。这两种格式的详情见附件一。不管格式如何,此步骤都会产生已知的对象长度(以位为单位)和Packed Object中编码的ID值的有序列表。从管理ID表中,确定每个ID的特征列表(例如辅助ID位的存在和数量)。
根据顺序中每个ID值调用的辅助ID位的数量,解析对象的辅助ID部分。根据此信息,创建Packed Object中编码的完全限定ID值(FQIDV)的列表。
根据每个FQIDV按顺序调用的Aux格式位的数量,分析对象的Aux格式部分。
解析Packed Object的数据部:
在Packed Object的字母数字子部中,数据字符的总数、字符映射的位长度以及后续二进制部分的位长度(表示数字和非数字二进制值)都不进行编码。因此,解码器必须遵循特定的过程才能正确解析字母数字部分。
当使用该过程对A/N子部进行解码时,解码器将首先对每个基中的非位映射值的数目进行计数(由各种前缀和后缀运行指示),并且(根据该计数)将确定对这些基中的这些值的数目进行编码所需的位的数目。然后,该过程可以从剩余的比特数计算显式编码的字符映射比特数。在分别解码各种二进制字段(使用的每个基对应一个字段)之后,解码器按照正确的顺序“重新交织”解码的ASCII字符。
A/N子部解码过程如下:
00表示Base 10值;01表示Base 13的字符编码;10表示之前在A/N首部中选择的非数字基,并且11表示先前选择的非数字基的扩展版本。0,DigitsCount加1,1,NonDigitsCount加1一旦解析了完整的FinalCharacterMap,就完全填充了InterleavedString。从ID列表上的第一个字母数字条目开始,将字符从交织字符串复制到每个这样的条目,在相应的Aux格式长度位指示的字符数之后或在交织字符串的末尾结束每个复制操作,以先到者为准。
;